
Samsung Open Source Conference Russia 2021
15 сентября 2021 г. компания Samsung Electronics провела международную конференцию Samsung Open Source Conference Russia 2021 (SOSCON Russia 2021). Это масштабное ежегодное мероприятие для open–source разработчиков, которое научно-исследовательское подразделение Samsung (Samsung Research) проводит с 2014 года. В этом году конференция впервые состоялась не только в Сеуле, но и в России при поддержке российского Исследовательского центра Samsung (Samsung R&D Institute Russia).В этом году студенты УЛ САПР посетили эту онлайн конференцию, и подготовили небольшие доклады по теме представленных технологий и разработок.
Intel (OpenFL)
Искусственный интеллект активно развивается в области здравоохранения. Исследователи из различных областей медицины разрабатывают алгоритмы, которые смогут помочь в решении многих задач. Наиболее активно ИИ применяется в патологии, радиологии и хирургии. Но чтобы обучать такие модели, требуется много разнообразных данных.
У текущих разработок есть один общий недостаток: они основаны на узкоспециализированных данных, модель нерепрезентативна на этапе применения, если в данных есть отличия (пол, возраст, место жительства и т.д.), а значит, плохо работает и не дает результата.
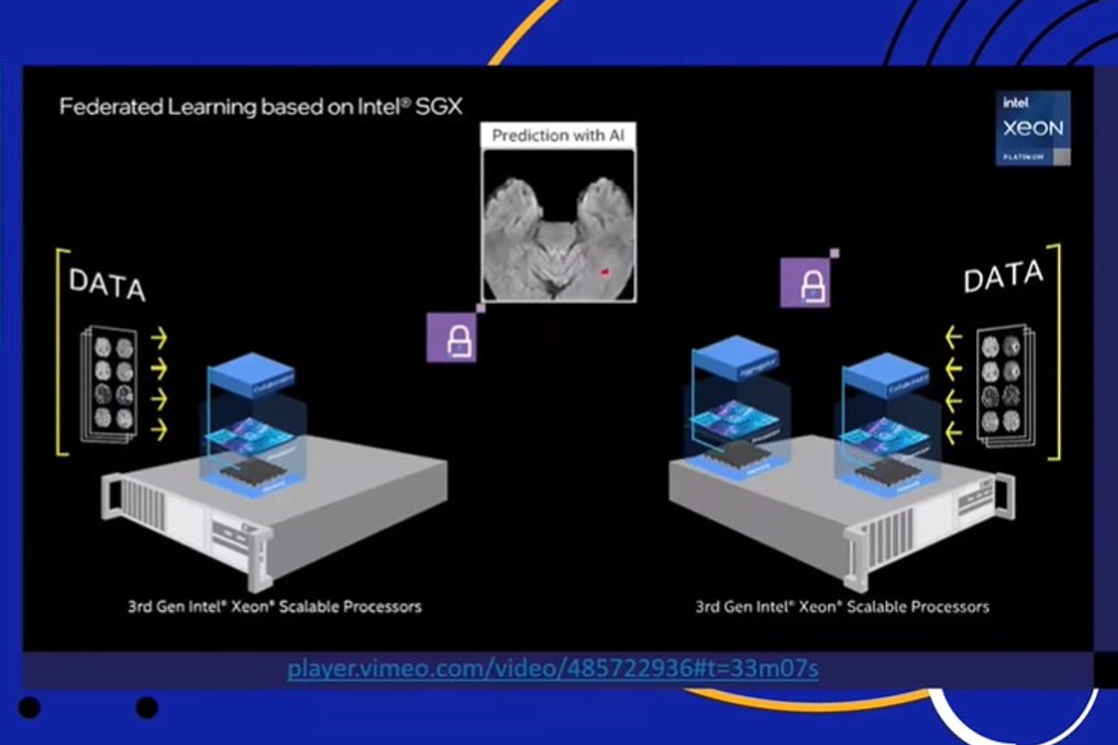
С данными в целом довольно много проблем: несбалансированные, дорогие, тяжелые, их трудно получить из-за множества законов о приватности. Ученые нашли выход: парадигма федеративного обучения. Краткий алгоритм таков: каждую ночь загружаем на устройства пользователей обновление приложения (иначе говоря, новые веса модели), дообучаем ее, отправляем веса на сервер и усредняем с другими моделями других пользователей. В таком случае не происходит трансфера данных, только весов модели, это не приводит к нарушению приватности, не является дорогой, долгой, тяжелой операцией.
Впервые такой подход был предложен компанией Google. Ее инициативу перехватили другие компании, в том числе Intel. Теперь компания содействует исследователям в области здравоохранения для создания эффективных и точных моделей. По сравнению с другими вариантами, федеративное обучение практически не уступает в качестве и работает быстрее.
В итоге Intel выпустил open source библиотеку для федеративного обучения – OpenFL. Она состоит из коллаборатора (модели с весами, которые обучаем под данные) и агрегатора (усреднение моделей). Эксперименты на новом железе компании Intel позволили увеличить секьюрность моделей, теперь проникнуть в модель в процессе передачи и каким-то образом ее изменить стало намного труднее.
ROS
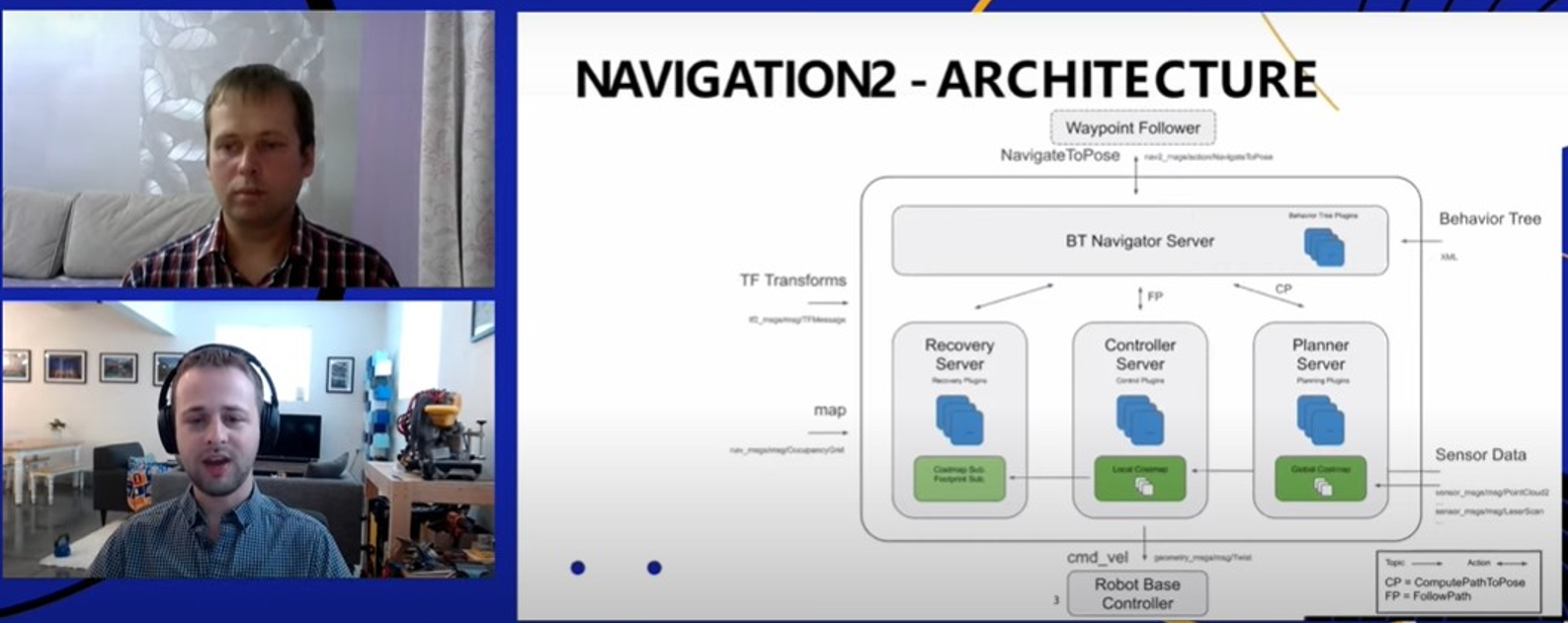
NAV2 – продуктовое решение для навигации ROS2 (второе поколение операционной системы для роботов). Этот способ навигации обеспечивает безопасный и надежный подход.
Навигация основана на алгоритме поведенческого дерева. ROS построена на независимых модульных серверах, может запускаться на разных ядрах или процессорах, либо в облаке. Алгоритмы обрабатывают запрещенные зоны, объезды препятствий, любые особенности пространства. Библиотеки позволяют реализовать поведение всех типов роботов.
Архитектура состоит из нескольких серверов: навигация, восстановление, контроллер, планировщик. Каждый сервер работает независимо, принимает задачу и возвращает в главный сервер результат, где находится сама логика навигации. Именно там содержится дерево поведения. Все данные приходят с датчиков (камер, сенсоров).
Кратко говоря, дерево работает так: мы проходим его, планируем путь и выбираем частоту обновления данных. Дерево поведения включает в себя обновление и восстановление пути, его также можно кастомизировать.
Информация о пространстве приходит роботу в виде карт затрат. На карты наносятся запрещенные зоны, ограничения скорости, барьеры и препятствия. Такие карты можно создавать в любом растровом редакторе. Цель в том, чтобы легко и быстро задавать, контролировать и изменять поведение робота.
Алгоритм формирования примерно такой: данные считываются с датчиков, формируется маска, затем с маски информация наносится на карты свойств, после чего карты затрат обновляются для формирования пространства у робота.
Обычно для локализации робота используются лазеры, однако, это довольно дорого. Есть и другие проблемы. Их решают алгоритмы SLAM (компьютерное зрение). Их работа напоминает человеческое зрение. Мы локализуемся, смотря на столы, стулья, стены и т.д. Роботы ориентируются на специальные точки. SLAM вычисляет положение камеры, в пространстве, используя сдвиги в системе координат. Когда робот смещается, мы вычисляем вектор сдвига точек и вновь локализуем робота. Чем больше точек захвачено камерой, тем точнее локализация. Алгоритм работает и при быстром движении, и в темноте.

Virtuozzo
Virtuozzo – контейнер, реализующий технологию легковесной виртуализации. Он позволяет создать независимые виртуальные окружения с общим ядром – хостом. В 2011 году компания включила в себя гипервизор, что позволило создать и контейнеры, и мощные виртуальные машины.
Параллельно развивалась платформа OpenVZ (набор патчей для Linux и несколько дистрибутивов). Возникла проблема: большой набор патчей требовал переноса на новую версию ядра ОС. Оказалось, что это скучная и трудная задача. В конце концов, компания инициировала передаче патчей непосредственно в upstream, в основную ветку ядра Linux. Продолжительное время компания даже входила в топ-20 контрибьюторов ядра, активно участвовала в создании cgroups, ставший основой для LXC и Docker.
Однако, спустя несколько лет компания вновь отделилась от гипервизора, что привело к острой нехватке рабочих рук. В итоге было решено объединить кодовую базу Virtuozzo и OpenVZ и перенести ее на open source платформу. Благодаря такому решению, впоследствии вес патчей уменьшился более чем в 3 раза, а некоторый функционал ядра системы был перенесен на платформы пользователей.
Open source позволяет на лету накладывать патчи на ядро Linux. Каждый патч уникален для конкретной версии и сборки ядра. Именно за это платят клиенты компании: настройка уникальных патчей, внедрение и техническая поддержка. База для ядра платформы и userspace – версия ядра Linux Red Hat. Это обеспечивает стабильность версий платформы, что также ценно для клиентов. Сейчас компания является активным контрибьютором пакетов ядра и продолжает развивать OpenVZ.
Deep Pavlov
Главное в индустрии разработки голосовых помощников – исполнять мечты людей. Interaction cost (IC) – цена взаимодействия пользователя с машиной, необходимая для достижения желаемого результата. Разработчики стремятся к zero IC.
Однако, современные ассистенты слабы. Они должны распознать речь, осознать, что хотел пользователь, сделать это и ответить пользователю голосом. Это очень сложная многоступенчатая система, каждый этап которой трудно довести до хорошего уровня.
Понимание и интерпретация человеческой речи – сложнейшая задача NLP. Цель Deep Pavlov – научить компьютер интерпретировать человеческую речь так, как это делают люди. Для этого команда участвует в конкурсах, самый яркий из которых – Amazon Alexa Prize.
Суть конкурса в том, что студенты должны реализовать социального бота, способного поддержать интересный разговор на разные темы хотя бы 20 минут и получить оценку не менее 4 баллов из 5.
Для этого участников обеспечивают фреймворком от Amazon – Go-bot, который позволяет создавать ботов. Но команда Deep Pavlov решила сделать собственную open source multiskill AI платформу. Ребята используют ее для создания собственного голосового ассистента. В итоге они сформировали более 30 скиллов и 10 аннотаторов, сделав платформу похожей на Google Assistant или Amazon Alexa. Deep Pavlov обладает серьезным преимуществом: система незаметно для пользователя выделяет все ключи в информации от пользователя. Как бы пользователь не высказался, система сможет незаметно выбрать скилл.
Ребята также столкнулись с существенной проблемой. Если response selector слишком умный, систему трудно масштабировать, если же слишком глупый, то система ошибается и не приносит результата. Для решения им пришлось запустить множество экспериментов.
Область способностей голосовых помощников невероятно огромна, человечество пока реализовало лишь верхушку айсберга. Команда Deep Pavlov стремится создать «автопилот» для conversational AI ассистента. Они уже разработали:
- entity linking;
- собственный фреймворк Go-bot;
- DFF;
- 3-level dialogue planning;
CatBoost
CatBoost - библиотека, разработанная компанией Яндекс и реализующая уникальный патентованный алгоритм построения моделей машинного обучения, использующий одну из оригинальных схем градиентного бустинга.
Работает на данных, организованных в табличном виде.
Очень проста в использовании без каких-либо сложных настроек.
Очень хорошо работает на маленьком объеме данных, но так же используется для решения проблем на больших данных
На примере гугл поиска: задача – показать релевантные сайты при поиске. Тип задачи: ранжирование.
Мы знаем, что сайты хранятся в виде документов, поэтому задача сводится к поиску релевантных документов, хранящихся на диске.
Входные данные в такой ситуации для нейросети это: особенности документа, функции запроса, функции запроса документа и другие особенности.
В данном алгоритме используются симметричные деревья, принцип работы которых показан на рисунке:
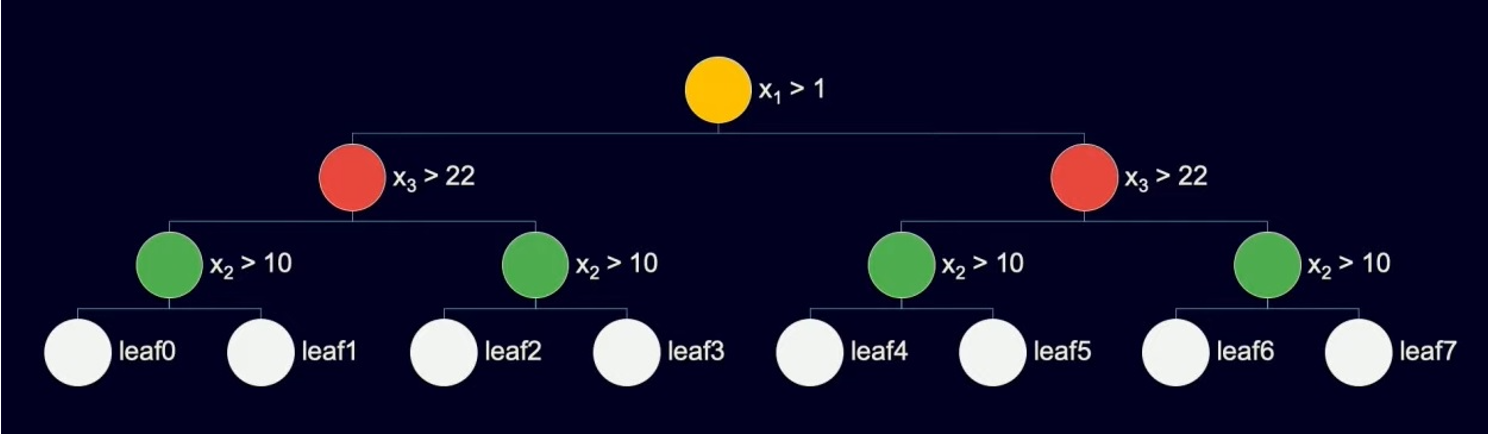
Так же с CatBoost’ом сравнивались другие сервисы такие как XGBoost и LightGBM, где CatBoost’a был определенным лидером во временных показателях.
Технология CatBoost на данный момент используется в таких сервисах как Яндекс.Поиск, Яндекс.Музыка, Яндекс.Погода, Алиса, Яндекс.Реклама и многие другие работающие по сей день сервисы.
Впервые CatBoost был разработан в 2017 году и благодаря комьюнити, которое дает активный feedback по данной технологии, к 2021 году CatBoost стал еще более эффективным.
Apache Airflow
Apache Airflow - платформа управления рабочими процессами.
На конференции Дина Сафина рассказывала, что Apache Airflow применяется в Mail.ru Group для улучшения качества игр, глядя на данные, которые собираются и анализируются как раз благодаря Apache Airflow
Технология построена на направленных ациклических графах (DAG – directed acyclic graph)
Таски запускаются после завершения предыдущих тасков (или в определенное время (настройка запуска зависит от разработчика)), при падении какого-либо таска появляется и отсылается сообщение об ошибке.
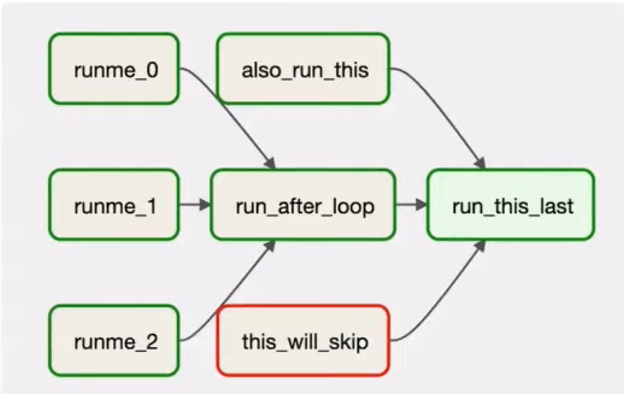
В архитектуру Apache Airflow входят:
· Веб-сервер – сервер, где хранятся данные
· Метаданные
· Sheduler – планировщик. Здесь указывается в каком порядке и когда должны запускаться таски
· Worker – какие таски должны исполнятся
· Executor – исполнитель. Он собственно и запускает указанные таски в указанное время и отсылает сообщение при неудачном запуске таска.
Преимущества Apache Airflow:
· Является Open-Source продуктом
· Хорошая документация
· Простой и понятный код, написанный на питоне
· Понятный и удобный интерфейс
Первая разработка Apache Airflow была в 2014 году и благодаря активному комьюнити (на данный момент 1500+ человек) развивается и по сей день.