Разработка автоматизированного классификатора коротких текстов
В настоящее время алгоритмы обработки естественного языка постоянно находят новые сферы применения. Среди большого спектра задач, классификация текстов является одной из наиболее часто встречающихся.
Проект является продолжением работы прошлого года. В 2020-2021 учебном году команде проекта удалось сравнить между собой несколько способов предобработки текстовых данных, видов моделей ( в том числе линейных, ансамблей деревьев и нейросетевых).

Заказчик проекта:
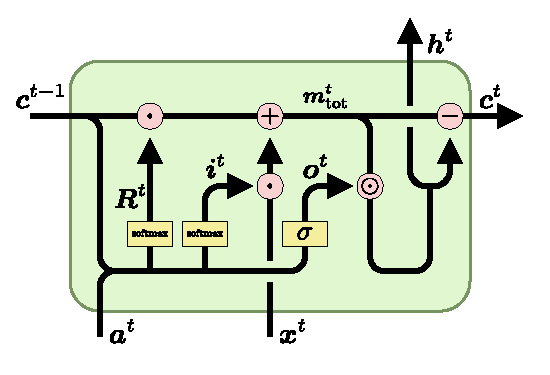
Заказчиком проекта выступает Всероссийский институт научной и технической информации РАН. Основной задачей прошлого года являлось построение классификатора способном решать задачу классификации аннотаций научных статей на 14 рубриках, которые соответствовали отделам ВИНИТИ. Наиболее качественной моделью оказалась связка нейросети BERT, созданной по архитектуре Transformer, в качестве селектора признаков с двухслойной рекуррентной сетью LSTM.
Учитывая опыт прошлого года было решено опробовать BERT на задаче классификации аннотаций к научным статьям по второму уровню ГРНТИ, в котором несколько сотен классов. Кроме того одна научная статья может относиться сразу к нескольким рубрикам. Такая постановка задача требует значительно большего вычислительного времени для получения результатов, достаточных для автоматизации классификации, в сравнении с задачей прошлого года.
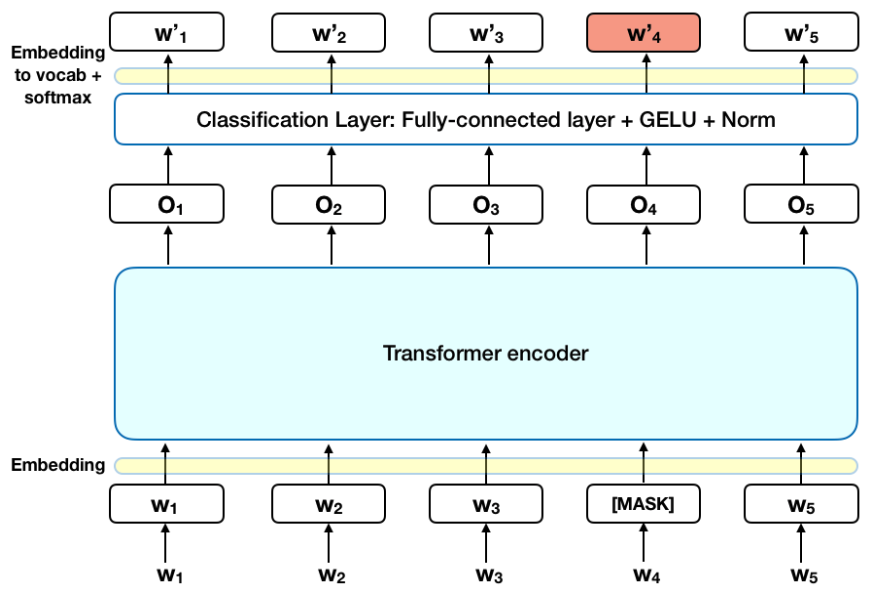
Исходя из сложности поставленной задачи было принято решение провести обучение BERT лингвистическим задачам на домене научных текстов. В качестве гипотезы было выдвинуто предположение о том, что модель заточенная решать лингвистические задачи на узконаправленной лексике справится с целевой задачей классификации лучше, чем базовая модель, обученная на широком корпусе русскоязычных текстов.
На данный момент команда проекта ведет работы по обучению лингвистической модели на домене научных текстов с использованием видеокарт лаборатории САПР. В следующей итерации две версии BERT будут обучаться решению целевой задачи классификации.

Команда проекта:
{kind=link}
{kind=link}
{kind=link}
Руководители проекта

Департамент компьютерной инженерии: Доцент
![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.