Разработка автоматизированного классификатора коротких текстов
В настоящее время сфера обработки естественного языка переживает бурный рост благодаря развитию технологий машинного обучения. Среди прочих категорий задач в Natural Language Processing (NLP), классификация текстов является одной из наиболее часто встречающихся.
Проект нацелен на исследование подходов к классификации коротких научных текстов, содержащих заголовок, краткую аннотацию и ключевые слова по теме статьи.
Заказчиком проекта выступает Всероссийский институт научной и технической информации РАН. Отсюда и нетривиальность стандартной задачи классификации текстов, которая объясняется сложной иерархической структурой рубрикаторов, большим числом классов, неравномерностью их распределения, а также возможностью причисления текста сразу к нескольким категориям.

Автоматизация классификации таких текстов позволяет решить проблему ручной категоризации, которая требует больших временных затрат и существования сразу нескольких отделов, специализирующихся на конкретных темах.
Целью проекта является модификация существующего программного обеспечения, которое позволяет классифицировать научные тексты ВИНИТИ РАН и глубокий анализ современного стека технологий, использующихся в анализе данных и машинном обучении. Предполагается, что исследование новых подходов к предобработке текста, векторизации и их применения в совокупности с усовершенствованными моделями классификаторов позволит добиться расширения функционала системы тестирования классификации.
В рамках исследований будут проверены алгоритмы стемминга и лемматизации для уменьшения словоформ и словаря токенов. Опробована Byte Pair Encoding токенизация и векторизация при помощи алгоритмов Bag of Words, Fasttext, Word2Vec, TF-IDF.
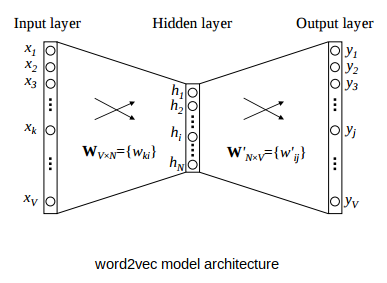
Для классификации будут использоваться как классические линейные модели (многоклассовая линейная регрессия), так и более сложные нейросетевые модели с полносвязными, рекуррентными и трансформер архитектурами.
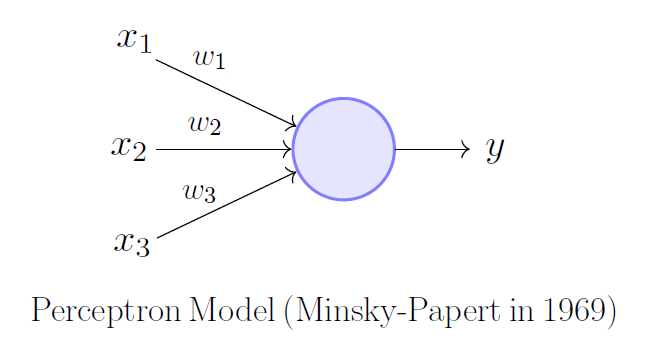
В результате ресерча будет составлена сводная таблица рассчитанных метрик, которые будут отражать качество классификации при различных комбинациях классификатор-метод обработки текста-эмбеддинг. На основании анализа данной таблицы будут выбраны подходы, дающие наилучшие результаты, которые впоследствии необходимо будет встроить в существующее программное обеспечение.
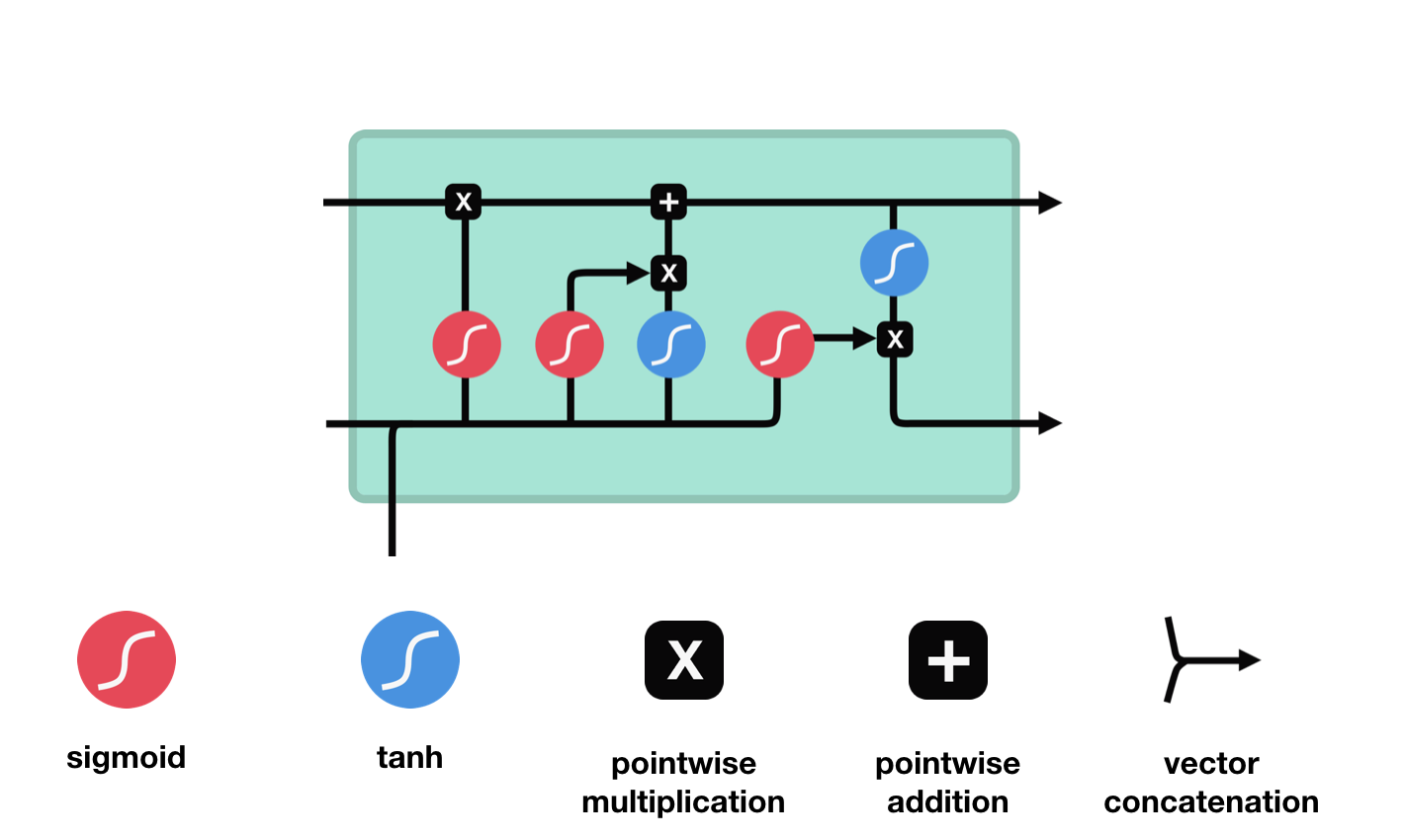
В настоящее время полностью завершена предобработка текста. Данные очищены от спецсимволов, цифр, пунктуации. Созданы датасеты для обучения моделей-трансформеров и датасеты для обучения моделей, с недостаточным количеством степеней свободы для работы с большим числом словоформ. Созданы модели векторизации слов, по алгоритмам TF-IDF, Word2Vec, Fasttext.
Изучены материалы по созданию рекуррентных и трансформер архитектур с использованием attention-механизма. Написаны и протестированы baselines для логистической регрессии и полносвязной нейросети. Проведены эксперименты по бинарной классификации с целью поиска оптимальной архитектуры и параметров моделей. Часть процедурных пайплайнов переписаны в классы для будущей библиотеки скриптов проекта.
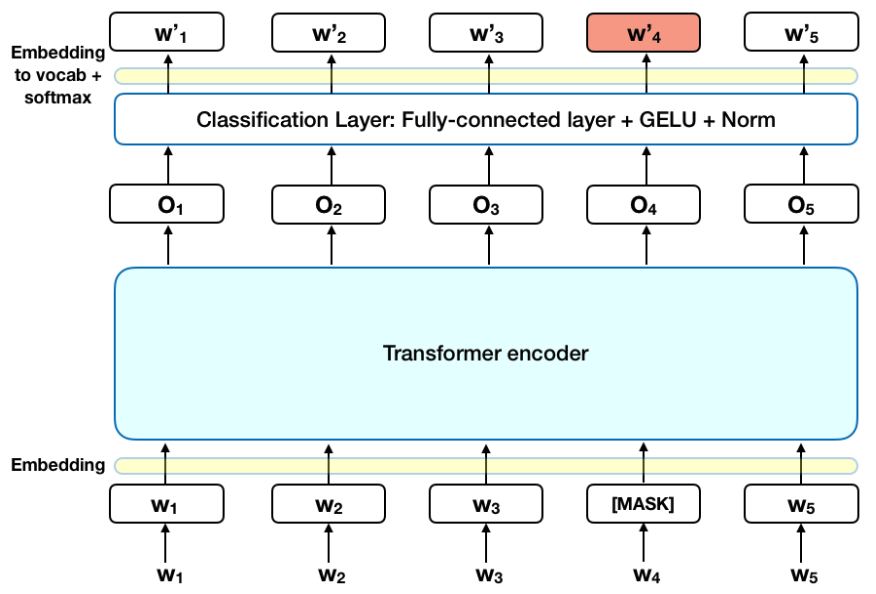
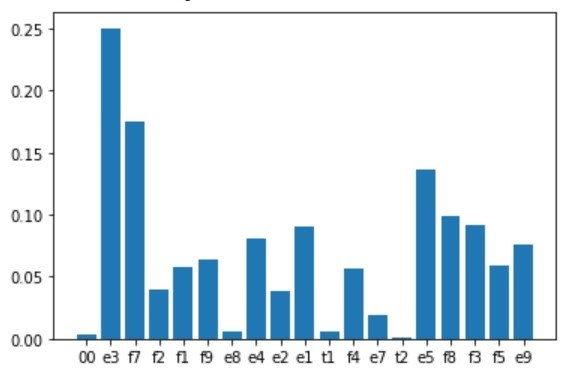
Ведется работа по тестированию уже написанных моделей на синтетически созданном датасете, при помощи oversampling’а, ввиду проблемы дисбаланса научных текстов по классам-темам. Данный шаг очень важен, ведь именно качество и сбалансированность данных влияет на стабильность обучения линейных и нейросетевых моделей.
В ближайшее время будут реализованы baseline для рекуррентных и трансформер классификаторов, после чего будет осуществлен поиск оптимальных гиперпараметров обучения для всех моделей с целью достижения наилучших метрик качества классификации.

Команда проекта
Алмакаев Александр - разработчик

Фото Алмакаева Александра (автор: Кусакин Илья Константинович)
Кусакин Илья - аналитик, лидер проекта

Фото Кусакина Ильи (автор: Исаченко Дарья Сергеевна)
Цурупа Александр - разработчик

Фото Цурупа Александра (автор: Алмакаев Александр Витальевич)
![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.