Development of an automated short text classifier
Currently, natural language processing algorithms are constantly finding new areas of application. Among a wide range of tasks, text classification is one of the most frequently encountered.
The project is a continuation of the previous year's work. In the 2020-2021 academic year, the project team managed to compare several methods of preprocessing text data, types of models (including linear, ensembles of trees, and neural networks) with each other.

Customer:
The customer of the project is the All-Russian Institute of Scientific and Technical Information of the Russian Academy of Sciences. The main task of the last year was to build a classifier capable of solving the problem of classifying abstracts of scientific articles in 14 headings, which corresponded to the departments of VINITI. The most high-quality model turned out to be the connection of the BERT neural network, created according to the Transformer architecture, as a feature selector with a two-layer recurrent LSTM network.
Taking into account the experience of the last year, it was decided to test BERT on the problem of classifying abstracts to scientific articles according to the second level of the SRSTI, in which there are several hundred classes. In addition, one scientific article can belong to several headings at once. This formulation of the problem requires much more computational time to obtain results sufficient to automate the classification, in comparison with the problem of the previous year.
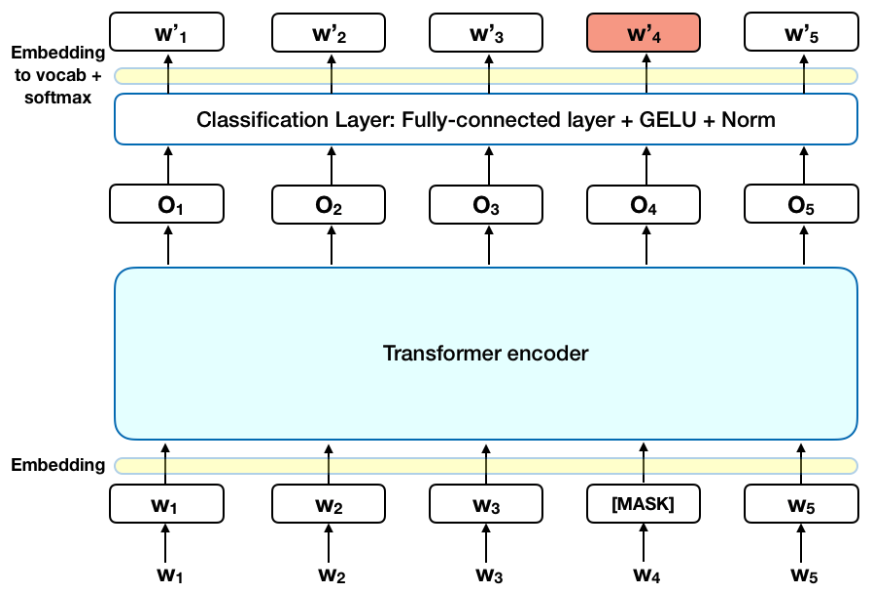
Based on the complexity of the task, it was decided to train BERT on linguistic tasks in the domain of scientific texts. As a hypothesis, it was suggested that a model sharpened to solve linguistic problems on a narrowly focused vocabulary will cope with the target task of classification better than the basic model trained on a wide corpus of Russian-language texts.

At the moment, the project team is working on training a linguistic model in the domain of scientific texts using video cards of the CAD laboratory. In the next iteration, two versions of BERT will be trained to solve the target classification problem.

The project team:



Project leaders

Senior Lecturer
Have you spotted a typo?
Highlight it, click Ctrl+Enter and send us a message. Thank you for your help!
To be used only for spelling or punctuation mistakes.