Development of an automated short text classifier
The field of natural language processing is currently experiencing explosive growth thanks to the development of machine learning technologies. Among other categories of tasks in Natural Language Processing (NLP), text classification is one of the most common.
The project is aimed at researching approaches to the classification of short scientific texts containing a title, a short annotation and keywords on the topic of the article.
The customer of the project is the All-Russian Institute for Scientific and Technical Information of the Russian Academy of Sciences. Hence the non-triviality of the standard problem of text classification, which is explained by the complex hierarchical structure of the rubrics, the large number of classes, their uneven distribution, and the possibility of assigning the text to several categories at once.

Automation of the classification of such texts allows us to solve the problem of manual categorization, which is time-consuming and requires the existence of several departments specializing in specific topics.
The aim of the project is to modify the existing software that allows the classification of scientific texts of VINITI RAS and in-depth analysis of the modern technology stack used in data analysis and machine learning. It is assumed that the study of new approaches to text preprocessing, vectorization and their application in conjunction with improved models of classifiers will expand the functionality of the classification testing system.
As part of the research, stemming and lemmatization algorithms will be tested to reduce word forms and token vocabulary. Tried Byte Pair Encoding tokenization and vectorization using the Bag of Words, Fasttext, Word2Vec, TF-IDF algorithms.
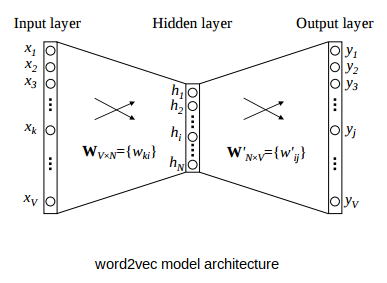
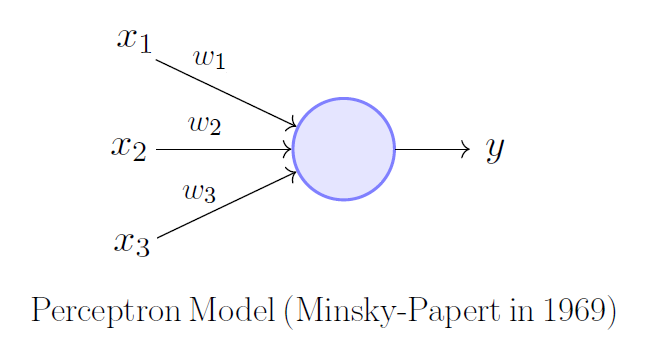
For classification, both classical linear models (multi-class linear regression) and more complex neural network models with fully connected, recurrent and transformer architectures will be used.
As a result of the research, a summary table of the calculated metrics will be compiled, which will reflect the quality of the classification for various combinations of classifier-text processing method-embedding. Based on the analysis of this table, the approaches that give the best results will be selected, which will subsequently need to be built into the existing software.
At present, the preprocessing of the text is fully completed. The data is cleared of special characters, numbers, punctuation. Datasets for training transformer models and datasets for training models with insufficient degrees of freedom to work with a large number of word forms have been created. Models of word vectorization have been created using TF-IDF, Word2Vec, Fasttext algorithms.
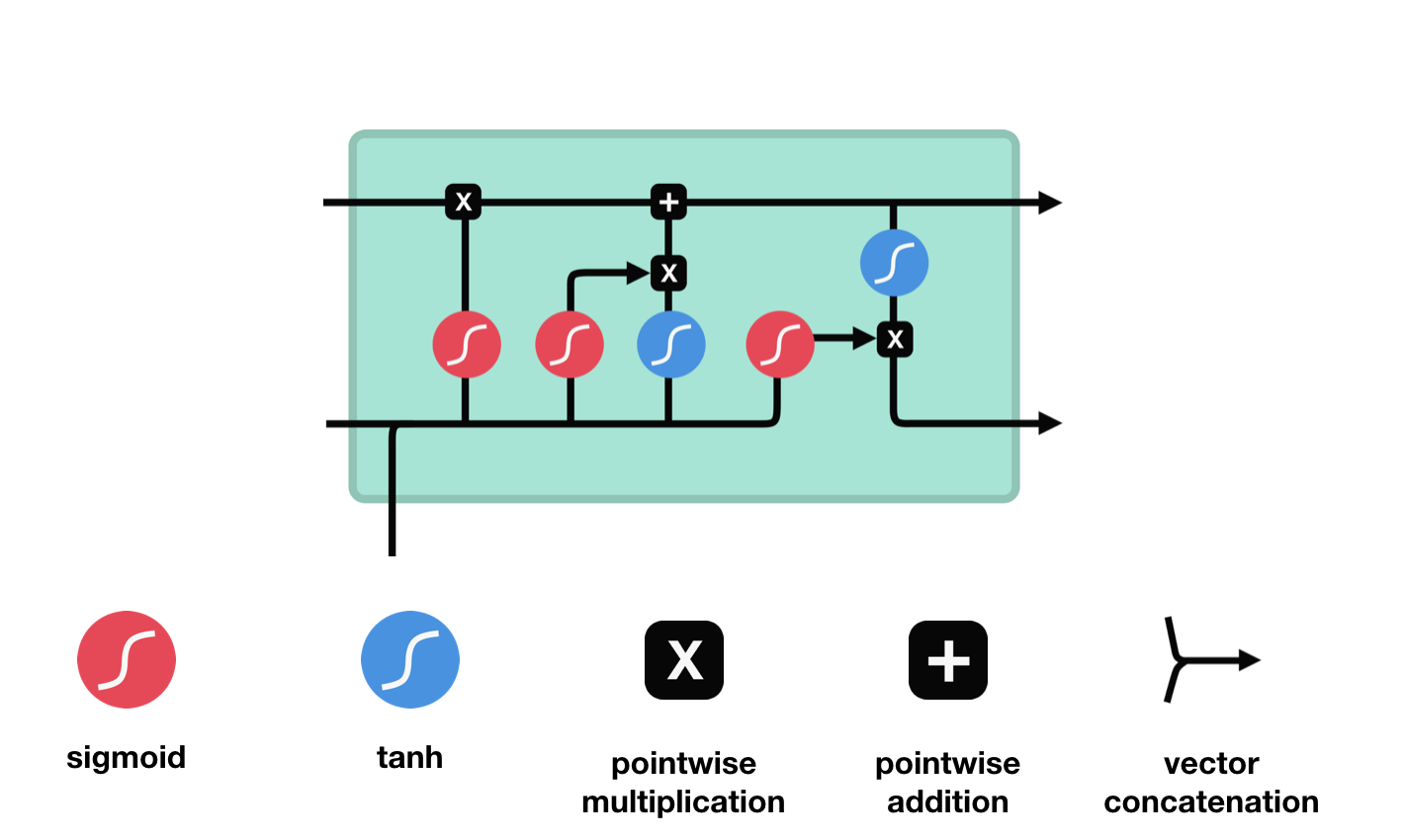
The materials on the creation of recurrent and transformer architectures using the attention mechanism have been studied. Baselines for logistic regression and fully connected neural networks have been written and tested. Experiments on binary classification were carried out in order to find the optimal architecture and parameters of the models. Some of the procedural pipelines have been rewritten into classes for the future script library of the project.
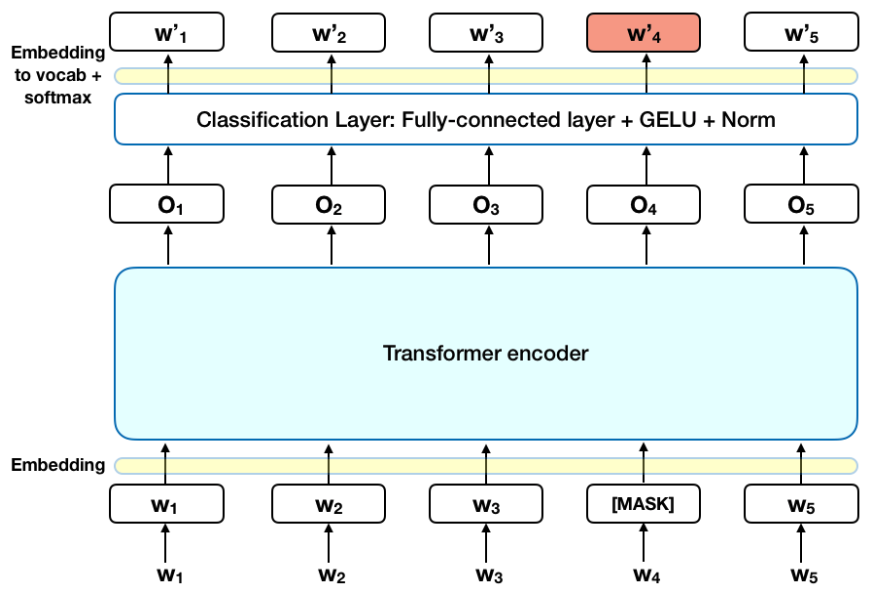
Work is underway to test the already written models on a synthetically created dataset, using oversampling, due to the problem of imbalance of scientific texts by topic classes. This step is very important, because it is the quality and balance of the data that affects the stability of training linear and neural network models.
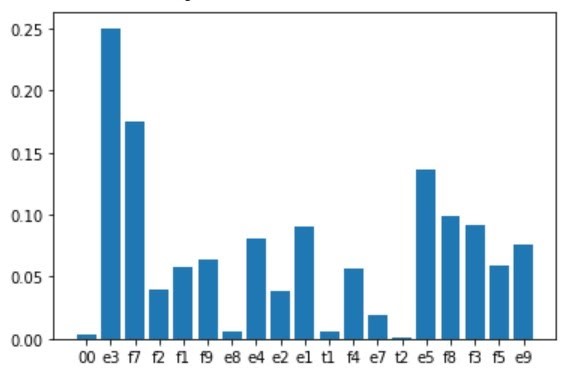
In the near future, the baseline for recurrent and transformer classifiers will be implemented, after which the search for optimal training hyperparameters for all models will be carried out in order to achieve the best classification quality metrics.

Project team
Almakaev Alexander - developer

Photo by Alexander Almakayev (author: Kusakin Ilya Konstantinovich)
Kusakin Ilya - analyst, project leader

Photo by Ilya Kusakin (author: Isachenko Daria Sergeevna)
Tsurupa Alexander - developer

Photo of Tsurup Alexander (author: Almakaev Alexander Vitalievich)
Have you spotted a typo?
Highlight it, click Ctrl+Enter and send us a message. Thank you for your help!
To be used only for spelling or punctuation mistakes.